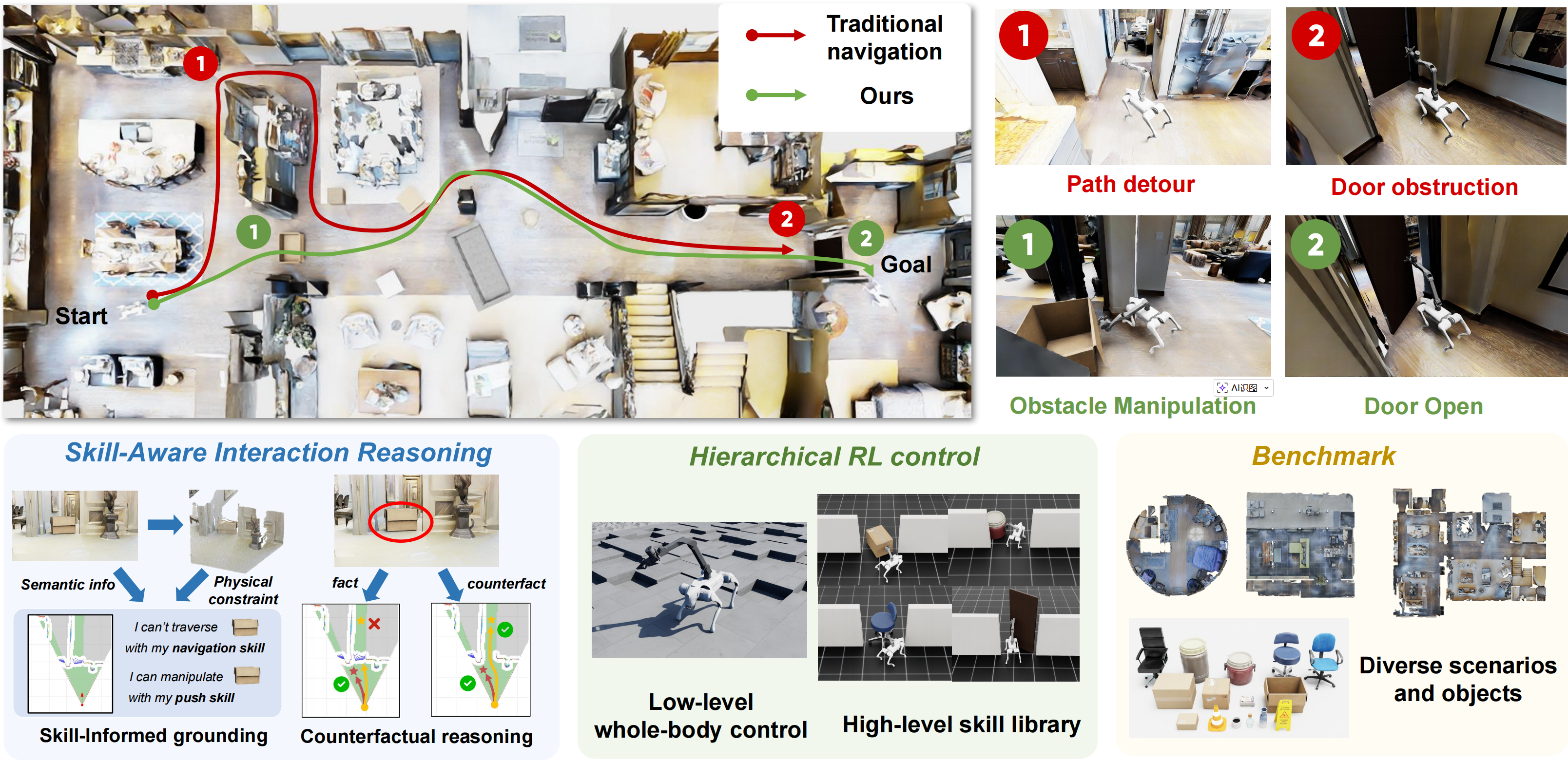
Interactive navigation requires robots to actively modify cluttered environments to create traversable paths, going beyond passive obstacle avoidance.
However, existing methods either depend on global maps and lack the reasoning capabilities to make interaction decisions from local observations, or are restricted to interactions with simple geometric objects, limiting their applicability in partially observable, unstructured environments.
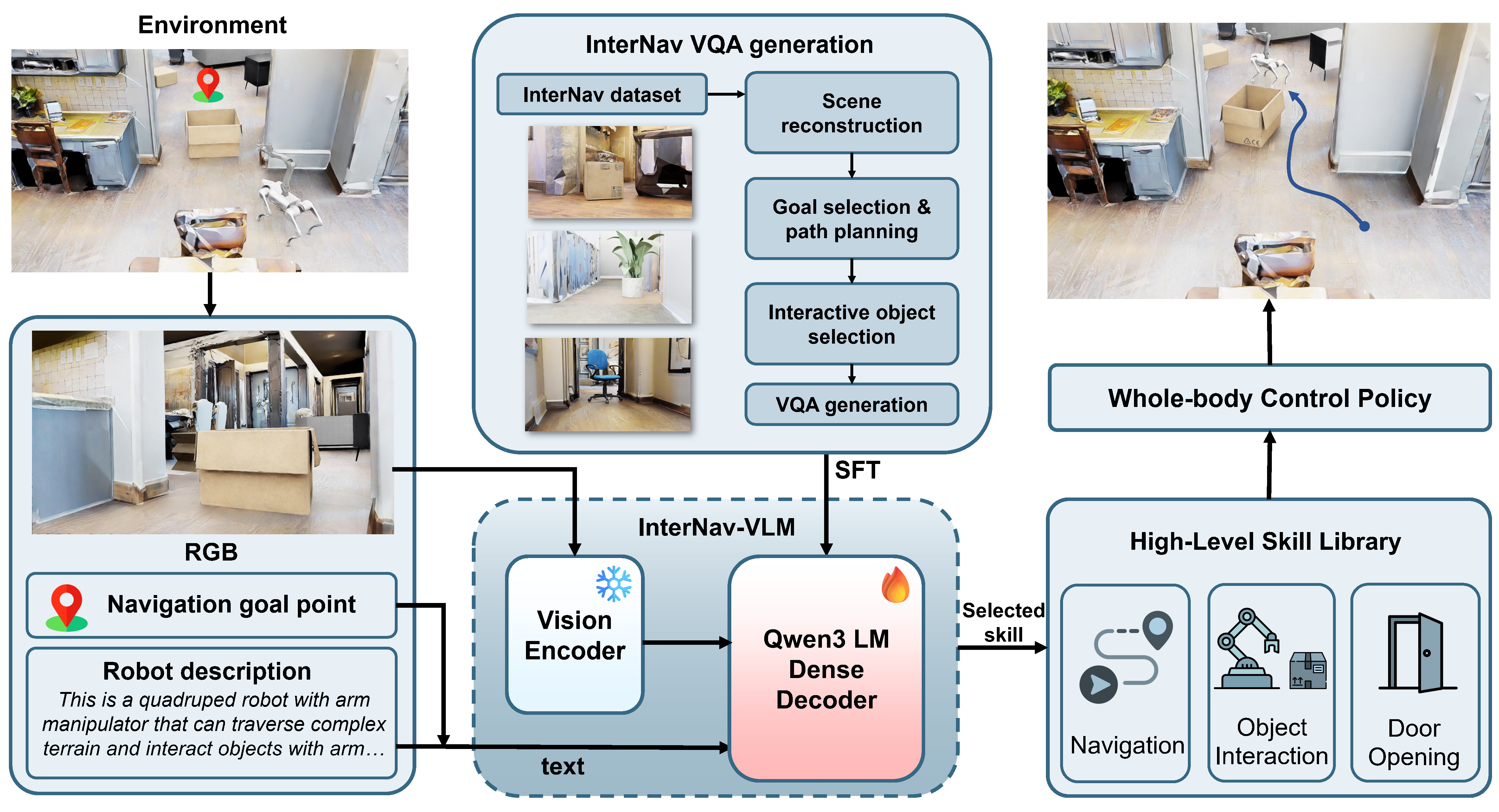
To address these challenges, we propose counterfactual interactive navigation, named CoIN, a vision-language model (VLM)-based hierarchical framework that integrates high-level interaction reasoning with low-level loco-manipulation policies for diverse objects.
Specifically, we propose CoIN-VLM, a VLM that internalizes counterfactual reasoning to evaluate the effect of object removal on goal reachability, thereby deciding when interaction is necessary and which object to interact with.
% This capability is distilled into the model via fine-tuning on the proposed InterNav dataset.
To further align such reasoning with the robot's physical capabilities, we inject robot skill descriptions into the VLM context and ground them into a metric-scale environmental representation, ensuring that the generated plans remain physically feasible.
To execute the generated high-level plans, we develop a comprehensive skill library through reinforcement learning, specifically introducing traversability-oriented strategies to manipulate diverse objects for path clearance.
Furthermore, a systematic benchmark in Isaac Sim is proposed to evaluate both the reasoning and execution aspects of interactive navigation.
Extensive simulations and real-world experiments demonstrate that CoIN significantly outperforms representative baselines, achieving a 17\% higher overall success rate and over 80\% improvement in complex long-horizon scenarios compared to the best-performing baseline, while exhibiting robust generalization across diverse object categories.